Содержание
Данный документ является руководством по применению подсистемы полнотекстового поиска (full text search, FTS) платформы CUBA.
Данное руководство предназначено для разработчиков, создающих на платформе CUBA приложения с возможностью полнотекстового поиска. Предполагается, что читатель ознакомлен с Руководством по разработке приложений, доступным по адресу www.cuba-platform.ru/manual.
Настоящее Руководство, а также другая документация по платформе CUBA доступны по адресу www.cuba-platform.ru/manual.
Подсистема полнотекстового поиска CUBA основана на фреймворке Apache Lucene, поэтому знакомство с его устройством будет полезным. См. lucene.apache.org/core.
Если у Вас имеются предложения по улучшению данного руководства, обратитесь пожалуйста в службу поддержки по адресу ru.cuba-platform.com/support/topics.
При обнаружении ошибки в документации укажите, пожалуйста, номер главы и приведите небольшой участок окружающего текста для облегчения поиска.
Полнотекстовый поиск (full text search, FTS) платформы CUBA предоставляет возможность неструктурированного поиска по значениям атрибутов сущностей и по содержимому загруженных файлов.
Особенностью реализации полнотекстового поиска CUBA является его ориентация на использование в бизнес-приложениях со сложными моделями данных. В частности, в результатах поиска отображаются не только сущности, напрямую содержащие в некотором атрибуте искомую строку, но и связанные сущности, при отображении которых используется этот атрибут. Например, если сущность Order (заказ) содержит ссылку на Customer (покупателя), и строка поиска содержит название покупателя, то в результатах поиска будет отображен и найденный покупатель, и заказ, на него ссылающийся. Это поведение является логичным для пользователя, который обычно видит название покупателя в экране редактирования заказа.
Результаты поиска фильтруются с учетом ограничений, накладываемых подсистемой безопасности платформы. То есть, если группа доступа текущего пользователя не разрешает загрузку некоторых экземпляров сущностей, они не будут отображатся в результатах поиска.
Подсистема полнотекстового поиска содержит два взаимосвязанных механизма: индексирование и собственно поиск.
Если в приложении подключен базовый проект fts и включено свойство cuba.fts.enabled, то при каждом сохранении в базу данных сущности, подлежащей индексированию, ее идентификатор записывается в очередь на индексацию - таблицу SYS_FTS_QUEUE.
Отдельный асинхронный процесс периодически извлекает идентификаторы изменившихся сущностей из очереди, загружает экземпляры сущностей и индексирует их. Индексация производится с помощью библиотеки Apache Lucene. Документ Lucene содержит следующие поля:
-
Имя сущности и идентификатор экземпляра.
-
Поле
all- конкатенация индексируемых атрибутов сущности, но только локальных и типаFileDescriptor. Если атрибут имеет типFileDescriptor, то индексируется содержимое соответствующего файла. Локальные атрибуты могут быть одного из следующих типов: строка, число, дата, перечисление. -
Поле
links- конкатенация идентификаторов сущностей, которые содержатся в ссылочных индексируемых атрибутах.
Под индексируемыми атрибутами понимаются атрибуты данной сущности и, возможно, связанных с ней сущностей, объявленные в дескрипторе FTS.
Индекс хранится в файловой системе, по умолчанию в подкаталоге ftsindex рабочего каталога приложения (задаваемого свойством cuba.dataDir), в стандартном варианте развертывания это tomcat/work/app-core/ftsindex. Расположение индекса можно изменить с помощью свойства cuba.fts.indexDir.
Поиск ведется по следующим правилам:
-
если искомая строка обрамлена кавычками, то ищется соответствующая фраза - набор таких же слов в том же порядке, игнорируя знаки пунктуации;
-
если искомая строка начинается с символа "*", то производится поиск по вхождению строки в любой части слова индексированных данных;
-
в противном случае поиск производится по совпадению искомой строки с началом слов индексированных данных.
Для русского и английского языка поиск производится с учетом морфологии.
Алгоритм поиска состоит из двух этапов:
-
Cначала искомая строка ищется в поле
allдокументов Lucene. Найденные сущности добавляются в список результатов. -
Если что-то найдено на первом этапе, то идентификаторы найденных сущностей ищутся в поле
linksдокументов Lucene. Найденные на втором этапе сущности также добавляются в список результатов.
Если строка поиска состоит из нескольких слов (и не обрамлена кавычками), то будет произведен поиск всех слов по отдельности по условию ИЛИ. То есть в результаты поиска попадут сущности, содержащие хотя бы одно из введенных слов.
Рассмотрим приведенный выше простейший пример со связанными сущностями Order и Customer.
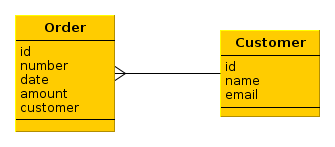
В данном случае, если все атрибуты объектов являются индексируемыми, при индексации двух связанных экземпляров Order и Customer будут созданы два документа Lucene примерно следующего содержания:
id: Order.id = "b671dbfc-c431-4586-adcc-fe8b84ca9617" all: Order.number + Order.date + Order.amount = "001^2013-11-14^1000" links: Customer.id = "f18e32bb-32c7-477a-980f-06e9cc4e7f40"
id: Customer.id = "f18e32bb-32c7-477a-980f-06e9cc4e7f40" all: Customer.name + Customer.email = "John Doe^john.doe@mail.com"
Теперь предположим, что ищется строка "john":
-
Сначала производится поиск в полях
allвсех документов. Будет найденCustomer, и добавлен в результаты поиска. -
Затем будет произведен поиск идентификатора найденного покупателя в полях
linksвсех документов. Будет найденOrder, и он также будет добавлен в результаты поиска.
В данной главе мы рассмотрим применение подсистемы полнотекстового поиска в приложении-примере Библиотека, который может быть загружен с помощью CUBA Studio.
Разобьем задачу на следующие этапы:
-
Подключим функциональность поиска к проекту, настроим вызов процесса индексирования и убедимся в его работоспособности.
-
Настроим конфигурационный файл FTS для работы с сущностями модели данных примера Библиотека.
-
Для иллюстрации возможностей поиска по загруженным файлам используем сущность
EBookи функциональность, описанную в руководстве Подсистема Workflow.
-
Запустите CUBA Studio, перейдите в окно и загрузите проект Library.
-
Откройте проект Library в Studio.
-
Откройте окно свойств проекта -> и в списке Base projects включите проект fts, затем сохраните изменения. Studio предложит пересоздать скрипты Gradle - согласитесь.
-
Запустите -> . На этом этапе будет произведена сборка приложения и оно будет развернуто на сервере Tomcat в подкаталоге
build/tomcat. -
Создайте базу данных приложения: -> .
-
Запустите сервер приложения: -> .
-
Откройте веб-интерфейс приложения по адресу http://localhost:8080/app. Войдите в систему с именем
adminи паролемadmin. -
Для того, чтобы включить функциональность полнотекстового поиска, в главном меню приложения откройте -> , найдите и откройте JMX-бин
app-core.fts:type=FtsManager, двойным щелчком откройте атрибут Enable и включите флажок Value.
После выполнения вышеописанных действий функциональность полнотекстового поиска подключена к приложению и готова к работе. Если выйти из системы и снова выполнить логин, в правой части верхней панели главного окна приложения появится поле поиска. Однако поиск не будет давать результатов, так как никакие данные еще не проиндексированы.
Для однократного запуска индексации текущего состояния базы данных (а точнее, сущностей, описанных в конфигурационном файле FTS по умолчанию), снова откройте в экране JMX-бин app-core.fts:type=FtsManager и вызовите последовательно сначала метод reindexAll(), а затем processQueue(). После этого поиск например строки "adm" должен выдавать следующие результаты:
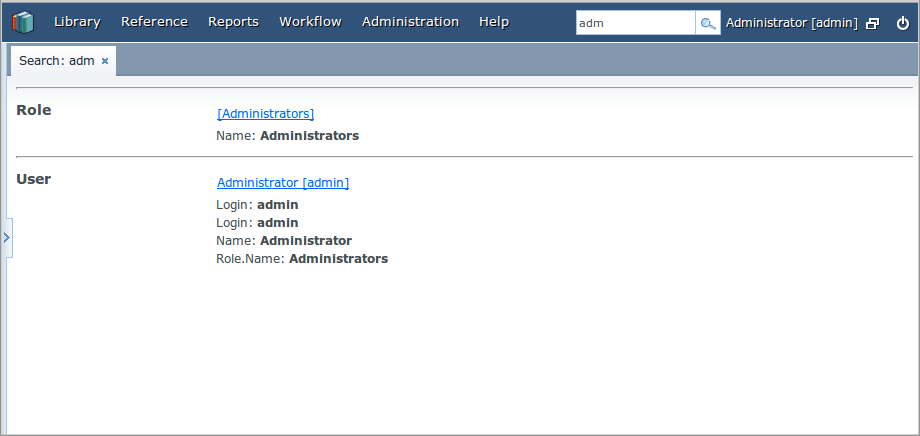
Для периодического вызова процесса индексирования удобно воспользоваться механизмом назначенных заданий платформы (см. Руководство по разработке приложений -> Назначенные задания CUBA).
Сначала необходимо активировать весь механизм запуска задач. Добавьте в файл app.properties модуля core проекта приложения следующее свойство:
cuba.schedulingActive = true
Перезапустите сервер приложения, войдите в систему пользователем admin, откройте экран , найдите и откройте JMX-бин app-core.cuba:type=Scheduling и убедитесь, что атрибут Active имеет значение true.
Далее откройте экран -> , нажмите и задайте следующие значения атрибутов новой задачи:
-
Defined by: Bean
-
Bean name: cuba_FtsManager
-
Method name: processQueue()
-
Singleton: true
-
Period, sec: 30
Сохраните задачу, выделите ее в таблице и нажмите . С этого момента каждые 30 секунд будет вызываться процесс индексирования измененных сущностей.
Автоматическое индексирование не затрагивает сущности, созданные до его запуска. Для индексации таких сущностей откройте экран и последовательно вызовите методы reindexAll() и processQueue() JMX-бина app-core.fts:type=FtsManager.
Создайте в каталоге исходных текстов модуля core файл fts.xml следующего содержания:
<fts-config>
<entities>
<entity class="com.sample.library.entity.Author">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.Book">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.BookInstance">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.BookPublication">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.LibraryDepartment">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.LiteratureType">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.Publisher">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.Town">
<include re=".*"/>
</entity>
</entities>
</fts-config>
Это файл конфигурации FTS, в данном случае включающий в индексирование все сущности предметной области со всеми их атрибутами.
Добавьте в файл app.properties модуля core приложения следующее свойство:
cuba.ftsConfig = cuba-fts.xml fts.xml
В результате индексироваться будут и сущности, определенные в платформе в файле cuba-fts.xml, и описанные в файле проекта fts.xml.
Перезапустите сервер приложения. На данном этапе полнотекстовый поиск должен работать по всем сущностям модели приложения, а также по сущностям подсистемы безопасности платформы: Role, Group, User.
Для иллюстрации возможностей поиска по содержимому загруженных файлов необходимо сначала подключить базовый проект workflow, добавить в проект сущность EBook, создать и пройти процесс сканирования книги, как это описано в руководстве Подсистема Workflow (см. раздел «Дополнительные материалы»). Далее в данном разделе предполагается, что в приложении создан экземпляр EBook и в результате выполнения процесса Book scanning загружен соответствующий файл с оригиналом книги.
Добавьте в файл fts.xml проекта следующие элементы:
...
<entity class="com.sample.library.entity.EBook">
<include name="publication.book"/>
<include name="attachments.file"/>
</entity>
<entity class="com.haulmont.workflow.core.entity.CardAttachment" show="false">
<include re=".*"/>
<exclude name="card"/>
<searchables>
searchables.add(entity.card)
</searchables>
</entity>
</entities>
</fts-config>
Для правильного отображения экземпляров EBook в экране результатов поиска добавьте классу EBook аннотацию @NamePattern:
@NamePattern("%s|publication")
public class EBook extends Card {
...
После этого перезапустите сервер приложения. Чтобы переиндексировать имеющиеся в базе данных сущности и файлы в соответствии с новой конфигурацией поиска, откройте в экране JMX-бин app-core.fts:type=FtsManager и вызовите последовательно сначала метод reindexAll(), а затем processQueue(). Все вновь добавляемые и изменяемые данные будут индексироваться автоматически, с задержкой, определяемой интервалом вызова назначенного задания, т.е. не более 30 секунд.
В результате, при наличии в базе данных книги с названием Alice's Adventures и загруженным оригиналом в формате PDF, результаты поиска строки "alice" выглядят следующим образом:
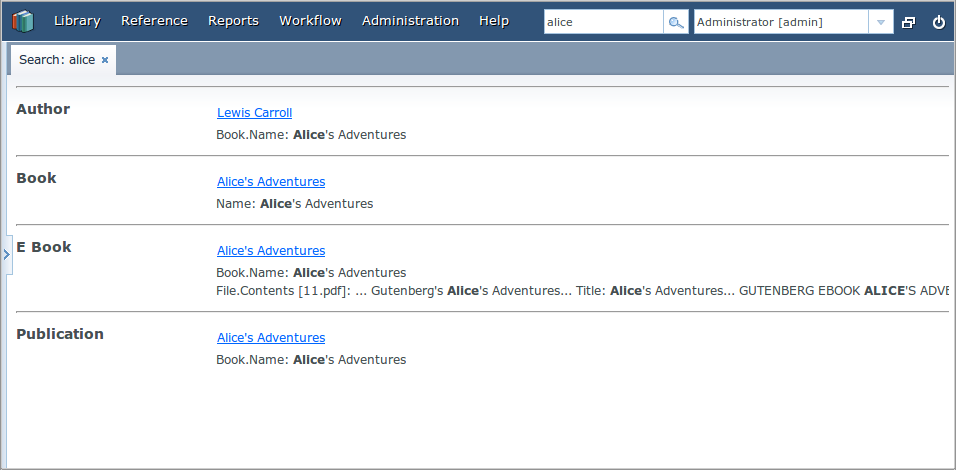
а результаты поиска строки "rabbit" так:
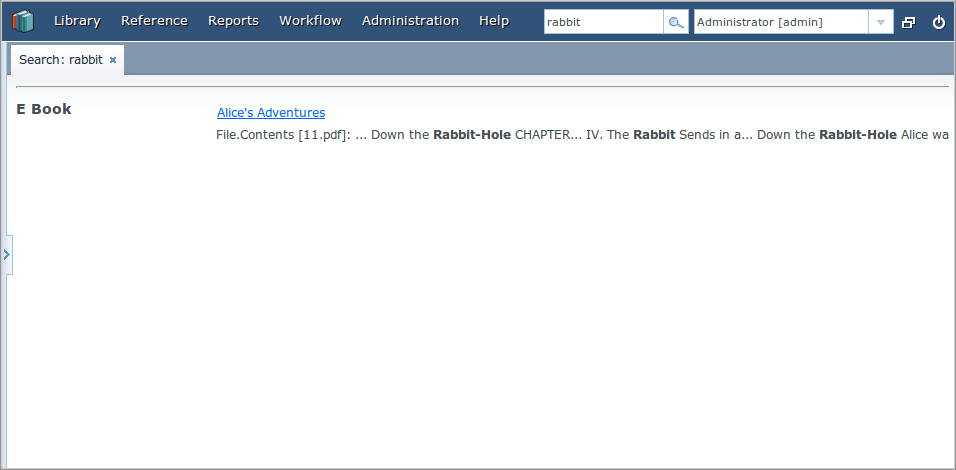
Файл конфигурации полнотекстового поиска представляет собой XML файл, как правило располагающийся в каталоге src модуля core, и содержащий описание индексируемых сущностей и их атрибутов.
Набор конфигурационных файлов FTS, включая определенные в базовых проектах, задается в свойстве приложения cuba.ftsConfig .
Рассмотрим структуру файла.
fts-config - корневой элемент.
Элементы fts-config:
-
entities- список сущностей, подлежащих индексированию и поиску.Элементы
entities:-
entity- описание индексируемой сущности.Атрибуты
entity:-
class- Java класс сущности. -
show- должна ли данная сущность показываться в результатах поиска самостоятельно. Значениеfalseиспользуется для сущностей-связей, которые не интересны пользователю сами по себе, но нужны, например, для связи загруженных файлов и сущностей предметной области. По умолчаниюtrue.
Элементы
entity:-
include- включить атрибут или несколько атрибутов сущности в индекс.Атрибуты
include:-
re- регулярное выражение для отбора атрибутов по имени. Отбираются только атрибуты следующих типов: строка, число, дата, перечисление. -
name- имя атрибута. Может быть путем (через точку) по ссылочным атрибутам. Тип не проверяется, однако если имя является путем, то конечный атрибут должен быть сущностью, а не простым типом (атрибут простого типа не имеет здесь смысла, он должен индексироваться в своей сущности).
-
-
exclude- исключить ранее включенный атрибут. Возможные атрибуты такие же, как в элементеinclude. -
searchables- Groovy-скрипт для добавления в очередь на индексирование произвольных сущностей, связанных с измененной.Например, когда изменяется (добавляется, удаляется) экземпляр
CardAttachment, мы должны также переиндексировать связанный с ним экземплярCard, так как сам собойCardв очередь не встанет, ибо не менялся.При запуске в скрипт передаются следующие переменные:
-
searchables- список сущностей, который нужно пополнять. -
entity- текущий экземпляр сущности, помещаемый в очередь автоматически.
Пример скрипта:
<entity class="com.haulmont.workflow.core.entity.CardAttachment" show="false"> ... <searchables> searchables.add(entity.card) </searchables> </entity> -
-
searchableIf- Groovy-скрипт для ограничения помещения в очередь некоторых экземпляров индексируемой сущности.Например, может быть не нужно индексировать старые версии документов.
При запуске в скрипт передается переменная
entity- текущий экземпляр сущности. Скрипт должен вернуть булевское значение -trueдля того чтобы индексировать текущий экземпляр,falseчтобы игнорировать его.Пример скрипта:
<entity class="com.haulmont.docflow.core.entity.Contract"> ... <searchableIf> entity.versionOf == null </searchableIf> </entity>
-
-
Пример файла конфигурации FTS:
<fts-config>
<entities>
<entity class="com.sample.library.entity.Author">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.Book">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.BookInstance">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.BookPublication">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.Publisher">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.EBook">
<include name="publication.book"/>
<include name="attachments.file"/>
</entity>
<entity class="com.haulmont.workflow.core.entity.CardAttachment" show="false">
<include re=".*"/>
<exclude name="card"/>
<searchables>
searchables.add(entity.card)
</searchables>
</entity>
</entities>
</fts-config>
В данном разделе перечислены свойства приложения, имеющие отношение к подсистеме полнотекстового поиска.
Все свойства, описанные ниже, являются параметрами времени выполнения, хранятся в базе данных и доступны в коде приложения через конфигурационный интерфейс FtsConfig.
- cuba.fts.enabled
-
Флаг, разрешающий использование функциональности FTS в проекте.
Значение данного флага может быть оперативно изменено с помощью атрибута Enabled JMX-бина
app-core.fts:type=FtsManager.Значение по умолчанию:
false - cuba.fts.indexDir
-
Абсолютный путь к каталогу для хранения индексных файлов. Если не установлен, используется подкаталог
ftsindexрабочего каталога приложения (задаваемого свойством cuba.dataDir), в стандартном варианте развертывания этоtomcat/work/app-core/ftsindex.Значение по умолчанию: не установлено
- cuba.fts.indexingBatchSize
-
Количество записей, извлекаемое из очереди на индексирование за один вызов метода
processQueue().Данное ограничение актуально для ситуации, когда в очереди на индексацию оказывается сразу очень большое число записей, например после выполнения метода
reindexAll()JMX-бинаapp-core.fts:type=FtsManager. В этом случае индексация выполняется порциями, что занимает больше времени, но создает ограниченную и предсказуемую нагрузку на сервер.Значение по умолчанию:
300 - cuba.fts.maxSearchResults
-
Максимальное количество результатов поиска.
Значение по умолчанию:
100 - cuba.fts.searchResultsBatchSize
-
Количество элементов в одной порции результатов поиска. Для показа следующей порции пользователь должен нажать на экране результатов.
Значение по умолчанию:
5